
In retrospect I should have paid more attention to knots when I was roughing out the feet for these saw horses 🙃 The Wood Owl bits didn’t care though, but paring the mortise with a chisel was a little tricky. 🪚

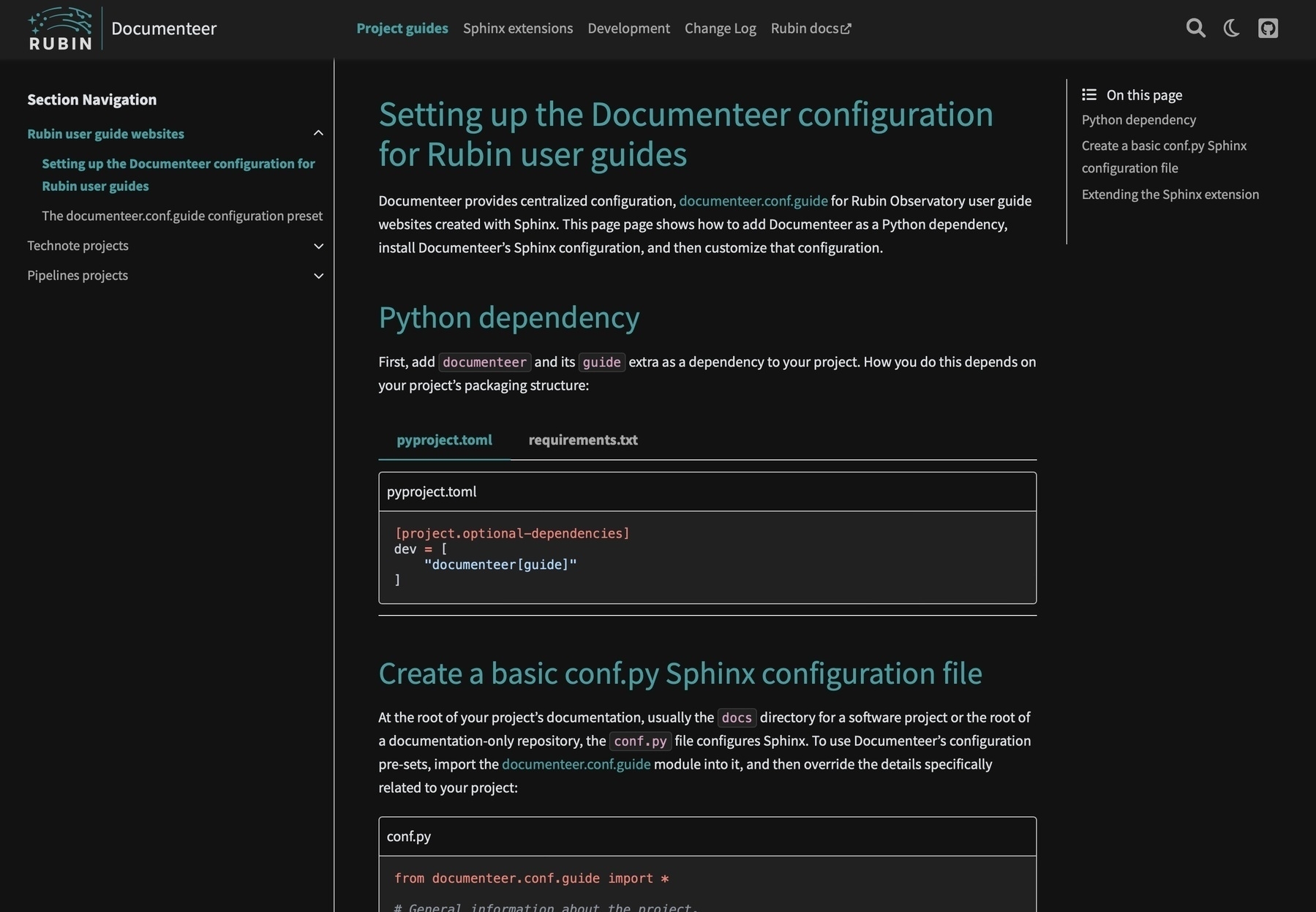
I’ve started to use the pydata-sphinx-theme for our next generation of Rubin Observatory documentation sites. Still needs more tweaks, but it’s a great foundation 😍
August 2022 in review
August is an odd month. It’s both the height of summer while also feeling like the end of summer up here.
Doing the work
This month, I got back into the user interface for Times Square on the Rubin Science Platform (Squareone). Now when you pull request changes to a notebook repository, Times Square will not only verify that notebooks execute cleanly, but it will also give you a link to view the rendered notebooks (lsst-sqre/squareone#84. I think this feature will make publishing notebooks to the Times Square platform easier for Rubin staff, and will promote a pull request-based workflow.
On YouTube, I stumbled upon a video by Chantastic (of React podcast fame) about setting up Storybook with Next.js. Storybook is an app for developing and documenting components (such as React components) in isolated contexts. I’ve known of Storybook for a while in the context of learning about design systems (hat tip to Atomic Design by Brad Frost), but I’d always considered it to be something for big teams that had the resources to set up design documentation infrastructures for their web projects. Well, it turns out that not only is Storybook amazingly easy to drop into an existing React application, but it also solves some glaring problems in my web development workflow. React components can have behaviours that depend on state. Working with state while developing components can be, quite frankly, a pain. With Storybook, I can now inject state into “stories” about my components, and even adjust that state in real time to see how the component adapts. You can see this initial Storybook related work in lsst-sqre/squareone#87 and lsst-sqre/squareone#93.
Towards the end of the month, I moved on to another Rubin web project: theming Rubin’s Sphinx documentation sites. We’re trying out pydata-sphinx-theme, which features a three column design (navigation — content — content headers) and a novel top navigation bar. Because that top navigation bar is populated from the root-level toctree elements of a Sphinx site, adopting pydata-sphinx-theme can take some content re-organization. I’ve implemented the theme in Documenteer, and I really like the result. My pull request to set up a Rubin configuration for Sphinx documentation is lsst-sqre/documenteer#129
Pursuits
Down in the wood shop (I can’t decide whether I want to call it a wood shop or workshop or even a studio) I made solid progress on my tool chest, based on the boarded chest in the Anarchist’s Design Book by Schwarz. I used my combination plane to make rabbets and nailed the chest walls together with fantastically-strong 2" cut nails. Then I used the combination plane to make tongue-and-groove joints for the bottom boards and nailed each board on, again with the 2" cut nails. I slightly mis-aligned one board while nailing it, and after failing to pull out the nails, realized that these cut nails have fantastic holding strength. I’m not worried about the chest bottom falling out. Now I’ve pivoted to making a set of low Krenovian saw horses to temporarily hold the chest at a workable height before I make a permanent stand (which could be months, years, or decades down the road).
Amanda and I got out for a bit more kayaking, and I shot and edited together a short video of us paddling around. It’s kind of dorky, but it’s also astonishing to think that we now have consumer-grade flying cameras that can follow people around perfectly.
Reading
Finished reading Hard-Boiled Wonderland and the End of the World by Haruki Murakami, The Book of M by Peng Shepard, and Boyfriend Material by Alexis Hall. Resumed the Gabriel Allon series with Amanda: we’re on The Rembrandt Affair by Daniel Silva.
Heavy rotation
The tracking on my U-Turn Orbit turntable went for a (literal) loop this month. Something about the anti-skip being a bit too strong, I think? But I really enjoyed listening to records of She & Him’s Melt Away: A Tribute to Brian Wilson and Lizzo’s Special. I must have had Sylvan Esso’s No Rules Sandy on repeat through most work days. And after watching Dua Lipa’s episode on Song Exploder, I dug a bit into her Future Nostalgia album.
Seven bees in this one sneeze weed. Our rewilding is working!

Finished reading: The Book Of M by Peng Shepherd 📚 It felt coincidental to read this right after The Hard-boiled Wonderland and the End of the World, with both speculating on the ideas of one’s shadow holding one’s soul/memories. A really lovely book with a similar slow slide into magic as Peng’s other book, The Cartographers.
A sunrise from a couple weeks ago that I got around to HDR stacking.

I’m kicking the tires on VS Code for web dev (vim+tmux user since… gosh, when did TextMate start to fall apart?). This tip for navigating splits with the keyboard is clutch → www.ryanchapin.com/vscode-ke…
Penetanguishene

I nailed together the sides of my tool chest. Used 6d (2 inch) cut nails with 2 mm pilot holes. Lots of clamping helped keep things aligned and prevented the nails from splitting the boards. 🪚


Finished reading: Boyfriend Material by Alexis Hall 📚 I sped-read this over the weekend on Amanda’s recommendation. Devestatingly adorable and full of good feels. Looking forward to the sequel!
Amanda’s purple coneflowers are a hit with the bees.

Shopping in the lettuce aisle.

Finished reading: The Hard-boiled Wonderland and the End of the World (Penguin International Writers) by Haruki Murakami. Found this book from a Carly Rae Jepson insta post (yes!) and glad I dove in to this sci-fi mediation on the mind. 📚
July 2022 in review
This is the first edition of what I intend to be a monthly round-up of the month. I’m doing this a bit for you — to keep tabs on what I’m up to — and also a bit for me to reflect on where my focus and effort are.FN
Doing the work
I started the month wrapping up basic GitHub Checks integration for Times Square, a dynamic Jupyter notebook publishing service for the Rubin Science Platform. Times Square is in semi-stealth mode (they’re both currently public open source), but I can’t wait to see how they get used by Rubin teams.
Next, I spent some time working on a new Cookiecutter template for “SQuaRE-style” Python packages that are published to PyPI. We’ve been informally copying the same patterns between our major libraries like Safir and Documenteer, but this template formalizes the basic structure for a SQuaRE package. It also provided us a chance to update our best practices. For instance, we’ve switched to pyproject.toml entirely for project metadata, as I wrote about on this blog. Second, I wanted to find a way to make our common GitHub Actions workflows more maintainable. It turns out that composite GitHub Actions are a low-overhead way of grouping sequences of actions together. The result is that the “user” workflows are both shorter and have less code to maintain since all the logic is now maintained in centralized actions. So far I’ve made three composite actions: lsst-sqre/run-tox, lsst-sqre/ltd-upload, and lsst-sqre/build-and-publish-to-pypi.
I refreshed some of the Kafka infrastructure that SQuaRE uses internally and provides to the rest of Rubin Observatory. First, I updated the packaging for Kafkit, our Python package for encoding Kafka messages in conjunction with the Confluent Schema Registry. Kafkit is also available on conda-forge now at conda-forge/kafkit-feedstock. I also overhauled Strimzi Registry Operator, our Kubernetes operator for deploying the Confluence Schema Registry on a Strimzi-deployed Kafka cluster. One bit of that refresh I’m really happy with is a PR that deploys Kafka, the operator, and a Schema Registry in minikube within GitHub Actions. This technique for building an application within minikube has a lot of potential as way of running integration tests for a lot of our microservices.
Lastly, I’ve also been thinking more about my online presence, including the viability of Instagram and my years-long absence from Twitter. I’ve started to invest effort into Micro.blog as a way of owning my content and cross-posting to Twitter and Instagram where it makes sense. Social media was really important for launching my career, but while working Rubin I’ve let it all drop off. It feel like it’s time to re-emerge, but on my own terms. I feel like we’re doing a lot of cool stuff at Rubin, and it’s time to share it with the world now that we’re getting closer to first light.
Pursuits
I got a DJI Mini 3 micro drone. The technology is astounding. I’ve been steadily learning its flying functionality and just barely digging into its camera functionality. I’m also playing around with editing the drone footage on my iPad with LumaFusion. It really feels like the future.
Reading
Finished The Cartographers by Peng Shepherd and Tongues of Serpents by Naomi Novik (with Amanda). Started reading Hard-Boiled Wonderland and the End of the World by Haruki Murakami.
Heavy rotation
The Garden by Basia Bulat (we’ve been playing this on vinyl at dinner), Formentera by Metric, and graves by Purity Ring.
Strimzi Registry Operator 0.5.0 released for Kafka
We just released version 0.5.0 of the Strimzi Registry Operator (see release notes). Strimzi Registry Operator helps you run a Confluent Schema Registry for a Kafka cluster that’s managed by the fabulous Strimzi operator for Kubernetes. The Schema Registry allows you to efficiently encode your Kafka messages in Avro, while centrally managing their schemas in the registry.
With the Strimzi Registry Operator, you deploy a Kubernetes resources like this:
apiVersion: roundtable.lsst.codes/v1beta1
kind: StrimziSchemaRegistry
metadata:
name: confluent-schema-registry
spec:
listener: tls
securityProtocol: tls
compatibilityLevel: forward
The operator deploys a Schema Registry server based on that StrimziSchemaRegistry resource and takes care of details like mapping the Kafka listener and converting the mutual TLS certificates into the JKS formatted keystore and truststore required by the Schema Registry.
We at Rubin Observatory’s SQuaRE team created the Strimzi Registry Operator back in 2019 to help us deploy an internal Kafka to power our ChatOps. Since then, this technology has become critical for other Rubin applications like the alert broker and the engineering facilities database (telemetry from the telescope facility). We’ve also gotten hints that the operator has been adopted by other Strimzi users, which we’re thrilled to hear of. Open source in action! ✨
To learn more, take a look at the Strimzi Registry Operator repository on GitHub.
A little father-daughter woodworking moment. 🐱🪚 Emma likes shavings… especially the long stringy ones from rounding off edges.

TIL you can create Note and warning admonitions in GitHub Flavored Markdown
httpie and GitHub Actions
I love httpie as an alternative to curl. It feels fresher, and is built for working with today’s HTTP APIs.
Anyways, I was using httpie’s @= feature for embedding file content in a JSON field within a GitHub Actions workflow and got an error:
Request body (from stdin, –raw or a file) and request data (key=value) cannot be mixed. Pass –ignore-stdin to let key/value take priority. See https://httpie.io/docs#scripting for details.
I didn’t think I was doing anything with passing standard input, and the command was running just fine locally, so I spent a good while finding possible solutions. Turns out I should have taken the error at face value. Somehow GitHub Actions runs commands in a way that triggers this stdin behaviour and need --ignore-stdin:
http --ignore-stdin --json post $REGISTRY_URL/subjects/testsubject/versions \
schema=@testsubject.json \
Accept:application/vnd.schemaregistry.v1+json
The fact is that one of America’s two major political parties appears to be viscerally opposed to any policy that seems to serve the public good.