
Last eggnog of the season 😢


Finished reading: Crucible of Gold by Naomi Novik 📚It’s kind of an old-school adventure novel. But with dragons that have the temperament of cats.
We finished watching Orphan Black 📺 last week and I just gotta proclaim: wow. Tatiana Maslany played 14 different characters, sometimes in the same scene (!), and I never felt out of it. Even the way she acted as one character acting as an another character — chef’s kiss.
Apparently storm chips are a Newfie thing but they work great for Ontario snow storms too.

Here’s a maple plywood feature wall I made for my workshop. 🪚 This will be the future home of my tool chest, some shelves for things like saws and (on the nerdier side) a network cabinet. I shiplapped the panels together by cutting rabbets with my router. As a fun highlight, I painted the rabbets green. To get the reveal between the panels just right, I used 5 mm plastic shims. This was also an opportunity to update the plugs and switches from the grimy ’70s hardware we had before.



I created a widget with Up Ahead for the latest Rubin Observatory milestones. It’s happening folks!

I just got into the beta for Reader by the Readwise folks and just a few minutes in I’m already astounded. It’s your read-later, but also your web research notebook, and your RSS feed and newsletter inbox. I also hear they’re thinking about a YouTube “highlighting” feature. 😍

The timeline isn’t settled. The @-mention isn’t settled. Nothing is settled. It’s 2003 again!
Robin Sloan’s A Year of New Avenues speaks to the renewed excitement I have about the web, and working on the web.
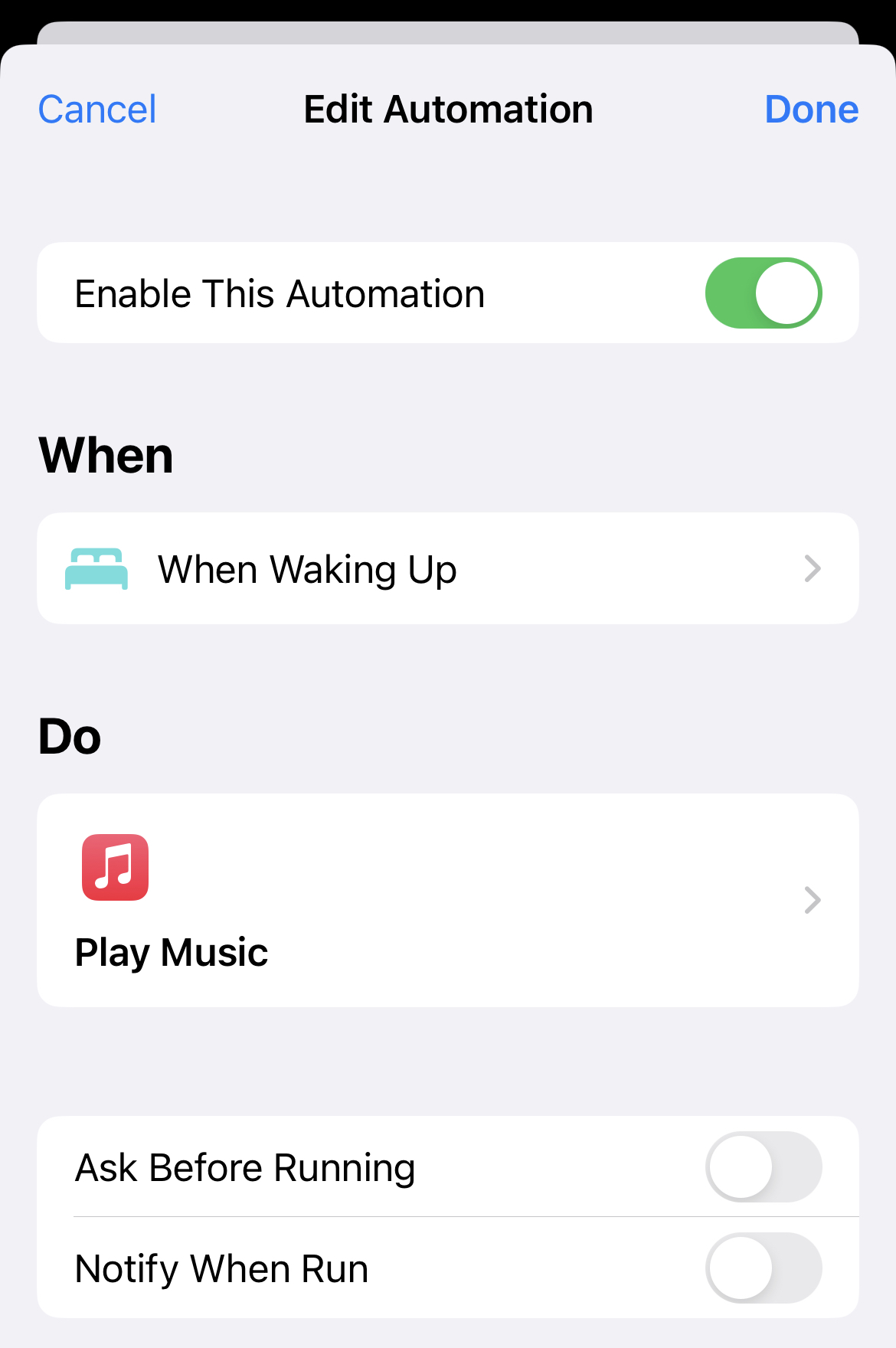
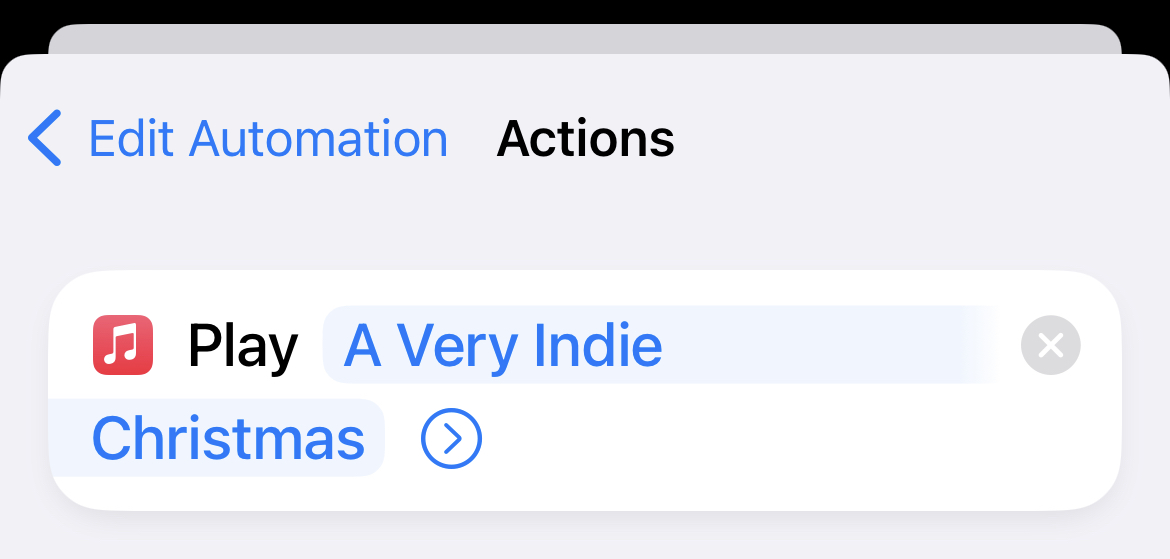
Inspired by @rosemaryorchard and @heyscottyj on Unnested Folders #90, I figured out how to create a “Personal Automation” in the Shortcuts app that starts playing Apple’s Indie Christmas playlist once I tap my alarm off. Delightful for the winter blahs!
I’m kind of surprised about Amazon Prime’s redesign with black on blue. I’m sure they ran a contrast checker but I feel a white on blue is the friendlier and clearer choice. Even iOS’s notifications automatically choose white text for the brand of blue!

Finished reading: The Golden Enclaves: A Novel (The Scholomance Book 3) by Naomi Novik 📚 We really enjoyed the series, and I loved how the third book veered into an allegory for human suffering inflicted by the greed and environmental destruction of an elite class.
Via Mac Power Users #668 I found out you can follow YouTube channels in most RSS services. I’ve always wanted a distraction-free way to follow channels and sort them into categories and I think this is it.
November 2022 in review
I missed the review for October, but I’m getting back on track. I’m finding these reviews, even if I’m the only person who interacts with them, are a useful for gauging progress. You can find my past monthly reviews here on the micro blog.
Doing the work
Documentation engineering for Phalanx
My highlight for October at Rubin Observatory was overhauling the documentation for Phalanx. Phalanx is how we deploy the Rubin Science Platform across different environments, whether it’s in Google Cloud or at institutional data facilities. The first phase of that work was to re-organize (and in many cases, edit and augment) the content into core categories (Overview, Application Developers, and Environment Administrators). I think the new theme is really working well for this purpose, with the top-level sections clearly defining different domains in the documentation.
On top of that narrative documentation, I built out two reference categories for applications and environments. These pages are intended to provide quick access to information about apps and environments. You can get a link to an application in an environment’s Argo CD, or see what environments an application runs in, or see what groups are configured with different authorization scopes, and so on. All of this information is already embedded within the Phalanx repository (an Argo CD GitOps repo, lsst-sqre/phalanx), so I engineered the Sphinx documentation build to pull the necessary information automatically. Essentially, in the Sphinx conf.py file I fire off a Python service that crawls the Phalanx repository’s Helm charts to collect datasets for each app and service. These get loaded in Jinja templating environments for sphinx-jinja, which I use to render out templated reStructuredText content, such as tables, just in time for the Sphinx documentation build. These are the things I really love about docs-like-code and a system like Sphinx — there are lots of entry points for creating very custom documentation tooling that enable us to document things accurately and efficiently.
Technote
In November, I started working on a brand-new project called Technote. It’s on GitHub at lsst-sqre/technote. At Rubin, we’ve been using technical notes or “technotes” since 2015 when we introduced them. You can read in SQR-000 why we created the technote format, and how we use it. The gist is that technotes are a lightweight documentation format for communicating within and across teams that is built on GitHub as the core platform for collaboration, and static web servers as the presentation platform (in our case, LSST the Docs, but you could use GitHub Pages or Read the Docs effectively too).
Initially, we created technotes just for ourselves in SQuaRE, but over time the format was organically adopted by more and more teams throughout the observatory. There are several hundred technotes already at Rubin (you can find them at www.lsst.io). Although the format took off, the Rubin technote platform stayed on the original Sphinx prototype theme I created in 2015 — a hacked version of the Read the Docs theme. And yes, you can now write technotes in LaTeX, but HTML-native technotes are still at the heart of the platform.
This month, at last, I carved out work time to start properly engineering the technote document format. At its core, the Technote package provides a Sphinx theme that’s geared towards single page articles (i.e., technotes) that have a title, document identifier, abstract, and other metadata like author lists and versioning information. Technote is a base layer, so organizations like Rubin and others can customize the branding and design of their documents. The long-term goal is to enable team members to write technotes in reStructuredText, Markdown, or Jupyter Notebooks, and render technotes in HTML, EPUB, and PDF (for archives). It’s early days, but I think there’s considerable potential in enabling teams to write documents on GitHub that are shared on the web.
Pursuits
It doesn’t feel like I’ve been making a lot of progress down in the woodshop, but my current goal is to organize the shop space into something that’s functional for both woodworking / making and also home storage.
Currently, I’m panelling a small section of wall under the stairs in maple plywood. I’ve ship lapped the panels and painted the rabbets with a splash of mint green. That wall will become the future home for my tool chest and a network cabinet.
Reading
Amanda and I have been reading The Golden Enclaves, the third book in Naomi Novak’s Scholomance series. They’ve made it out of the Scholomance — now they’re facing the “real” world of wizards.
I’ve also been on a personal knowledge management kick, trying to figure out how to build a system for gathering information and making it accessible to me. I read Tiago Forte’s Building a Second Brain, which I think is a system that has a lot of good ideas. I’ve also been re-reading How to take smart notes by Sonke Ahrens, who teaches the Zettlekasten system of literature notes and atomic permanent notes — and leaves project management aside. In some ways Ahrens’ approach is more appealing because I can see it scaling more easily than Forte’s approach of literally moving notes from one bucket to another. I’m working out how all of these ideas can become a personal knowledge management system for myself, centred around DEVONthink.
Heavy rotation
Carly Rae Jepson and Taylor Swift both released albums on the same day, so apologies to other artists but these are all I’ve been listening to lately.
I’m in love with CRJ’s The Loneliest Time, and the title track with Rufus Wainright is my personal hit for the year. I also especially love Surrender My Heart, So Nice, and Shooting Star. Actually, every song is a banger. Full stop.
On screen
Season 6 of the Great Canadian Baking Show was a fantastic display of diversity. Don’t pay any attention to the dribble that the Walrus publishes about it.
Sort of season 2 on CBC Gem started and it’s a brilliant masterpiece.
We’ve also started watching Orphan Black, which I missed out on when it originally aired. Tatiana Maslany’s acting is astonishing.
So why do my colleagues often pray whenever I answer their question on Slack? 🙏
People who write extensively about note-writing rarely have a serious context of use
— Andy Matuschak via Maggie Appleton. 💬
i.e. what works for productivity writers probably needs to be re-engineered for a software developer or woodworker.
On the PKM beat, it seems like Apple Books in iOS 16 doesn’t permit exporting a book’s notes and highlights anymore (you can only share one highlight/note at a time). And on top of that, the delightful page turn effect is gone. Time to go to Kindle? 🤷♂️
This new Interactive guide to flexbox by Josh Comeau is so good. Hopefully it’ll click in my head now… I’ve been using flexbox for years and I still look up CSS Tricks’ guide every time.

Currently reading: Building a Second Brain by Tiago Forte 📚 I’ve slowly been adopting DEVONthink for project notes and reference material for work, home, and even woodworking. I’m hoping to refine my system with Tiago’s book.
It’s really cool to see how GitHub Codespaces and science platforms like Rubin’s are all working towards the same goals of reducing set up time and eliminating computing resource bottlenecks by providing cloud-based containerized environments.
One of the surprising things I’ve learned after moving back to Canada is brokerage fees when buying things online from the US. The brokerage fees that UPS changes are about 220% of the taxes.
Another new-ish gem in the Sphinx ecosystem, sphinxcontrib-mermaid makes it easy to drop Mermaid diagrams-as-code into docs, even Python docstrings.

The Sphinx documentation ecosystem is getting better and better. Latest example: autodoc_pydantic drops in for documenting Pydantic schemas. 🥳
Can I admit something? I haven’t yet given Taylor Swift Midnights a proper spin yet. The whole week has been Carly Rae Jepsen The Loneliest Time on repeat. What a gem.
September 2022 in review
Doing the work
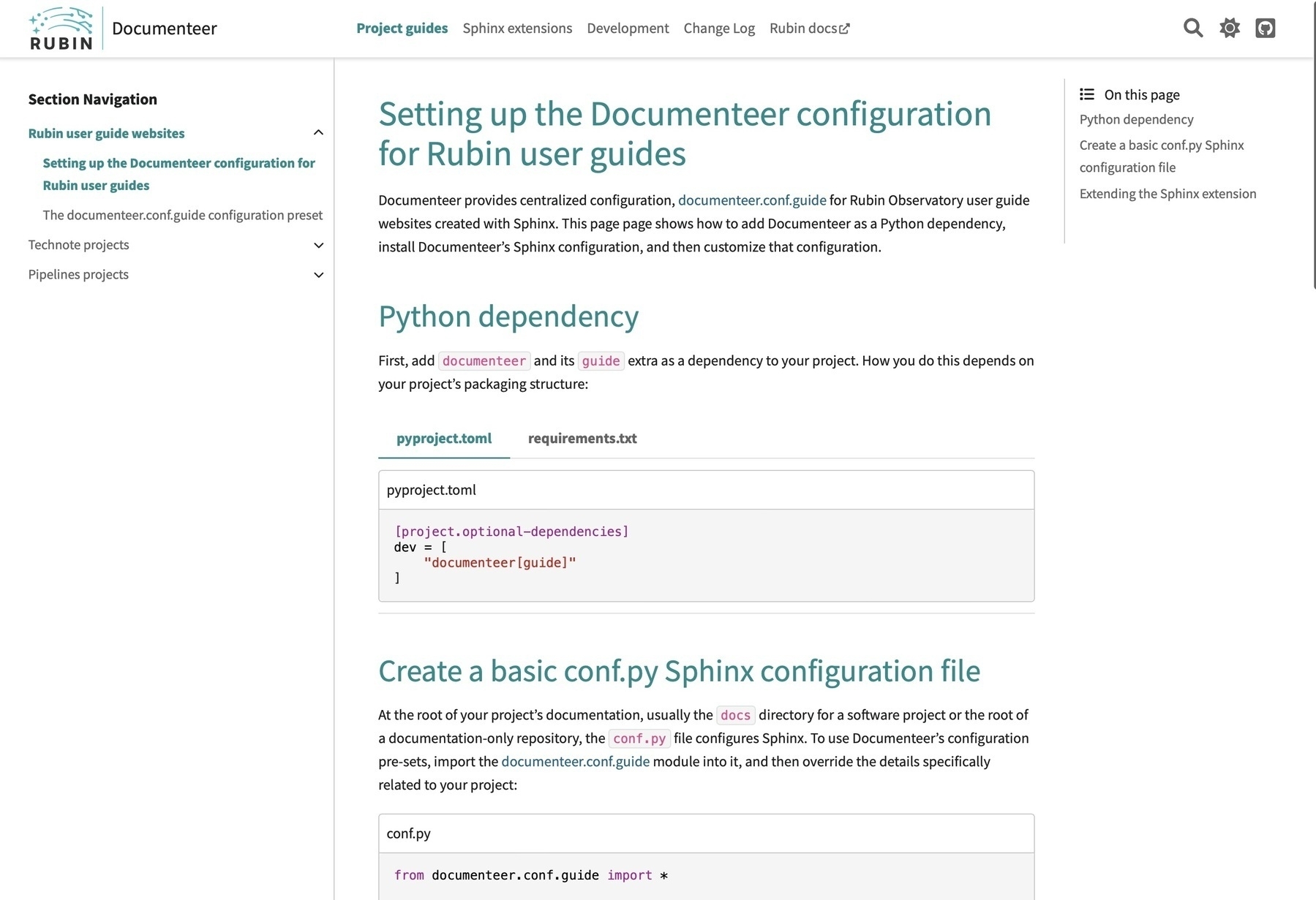
September was all about shipping the new system for Rubin Observatory user guides in Documenteer. When I first started working on documentation for Rubin back in 2015, I always struggled with getting Sphinx documentation themes to do exactly what we wanted. For years I told my colleagues we’d fix all the issues — from typography to navigation to branding and more… eventually. Now I think we’ve finally got to a point where we are shipping polished documentation sites we can really be proud of. And the best part is I didn’t have to do the ground-up production of a custom Sphinx theme. Instead, we used the new and awesome PyData Sphinx Theme as an open source foundation. I really appreciate how the PyData folks have thought through the customization and branding use cases. For example, CSS custom properties make it a snap to apply Rubin’s brand colours in both light and dark themes. In the past this would have been a fraught task that yielded rather fragile CSS overrides.
What I spend most of the month though was productizing the user guide theme and configuration for the Rubin organization. Sphinx documentation projects use a Python module, called conf.py for configuration. To help Rubin projects use the same core configuration (and therefore benefit from consistent features and branding), we provide a configuration module in Documenteer that each project can import into its conf.py file:
from documenteer.conf.guide import *
Each project still needs to customize its Sphinx configuration in many ways. The technically simple way to do this is to have each project extend the core configuration in its conf.py file. But in some cases this is tricky because you need to customize existing lists and dictionary provided by the core configuration. It’s just awkward and error prone.
What we’ve done instead is introduced a file, called documenteer.toml, where a user can configure their project. The documenteer.conf.guide configuration merges this information with the Sphinx conf.py file for you. This lets us also do smart and semi-automated configuration. For instance, if a project is a Python package, the configuration can automatically pull out the project’s name, version, and repository URL.
[project]
title = "Documenteer"
copyright = "2015-2022 Association of Universities for Research in Astronomy, Inc. (AURA)"
[project.python]
package = "documenteer"
Overall, the documenteer.toml file means we can document and support a well defined set of configuration that each Rubin documentation project can manipulate.
Within Rubin Observatory, this is the sort or work that I find both satisfying and also really powerful from an organizational perspective. We’re able to take together elements of the open source ecosystem, edit and mix them together, and then provide and document a simple interface that other members and teams in the observatory can use in their own work. Rather than personally running all the documentation sites for the entire observatory, I can help the entire observatory create their own documentation. That’s how a small team like ours can have an outsized influence on an organization.
Pursuits
Amanda and I joined our friend couple on a hike to McCrae Lake Conservation Reserve, a popular site just north of us that’s the beginning of the Canadian shield country. The purpose of the trip was to take some wedding anniversary shots for our friends, and they turned out adorably cute. I also flew the drone and managed to capture a glimpse of a beaver near it’s lodge. I put the video up on YouTube.
I’m getting the hang of Lumafusion and even had some fun mixing some nature sounds and atmospheric sound tracks from the Audiio library. Video editing gets easier the more you do it, and I could see this being something I want to keep doing more.
Down in the workshop I’ve been slowly getting the sliding trays for the tool chest project. I got the tray slides in (made from white oak) and milled the pine stock for the trays themselves.
Reading
Finished reading The Thursday Murder Club by Richard Osman, After Dark by Haruki Murakami, and Make Time by Jake Knapp and John Zeratsky. Make Time is a quick book with loads of strategies to experiment with for getting better at focusing. Amanda and I started reading Husband Material by Alexis Hall together, which is the sequel to Boyfriend Material.
Heavy rotation
Amanda and I went to see Carly Rae Jepson play in Ontario Park in Toronto for her So Good tour. And it was so good. Every song of hers is a hit and she sounded amazing with her band. Bleachers opened for her and it was really cool to see Jack Antonoff for the first time.
On screen
We’ve been watching Only Murders in the Building, a hilarious take on the true crime podcast phenomenon with Steve Martin, Martin Short, and Selena Gomez. Enough said!
Embracing the last bits of summer up here.

I’ve been working on my tool chest this week and installed these two tier tray runners in white oak.



In retrospect I should have paid more attention to knots when I was roughing out the feet for these saw horses 🙃 The Wood Owl bits didn’t care though, but paring the mortise with a chisel was a little tricky. 🪚

I’ve started to use the pydata-sphinx-theme for our next generation of Rubin Observatory documentation sites. Still needs more tweaks, but it’s a great foundation 😍
August 2022 in review
August is an odd month. It’s both the height of summer while also feeling like the end of summer up here.
Doing the work
This month, I got back into the user interface for Times Square on the Rubin Science Platform (Squareone). Now when you pull request changes to a notebook repository, Times Square will not only verify that notebooks execute cleanly, but it will also give you a link to view the rendered notebooks (lsst-sqre/squareone#84. I think this feature will make publishing notebooks to the Times Square platform easier for Rubin staff, and will promote a pull request-based workflow.
On YouTube, I stumbled upon a video by Chantastic (of React podcast fame) about setting up Storybook with Next.js. Storybook is an app for developing and documenting components (such as React components) in isolated contexts. I’ve known of Storybook for a while in the context of learning about design systems (hat tip to Atomic Design by Brad Frost), but I’d always considered it to be something for big teams that had the resources to set up design documentation infrastructures for their web projects. Well, it turns out that not only is Storybook amazingly easy to drop into an existing React application, but it also solves some glaring problems in my web development workflow. React components can have behaviours that depend on state. Working with state while developing components can be, quite frankly, a pain. With Storybook, I can now inject state into “stories” about my components, and even adjust that state in real time to see how the component adapts. You can see this initial Storybook related work in lsst-sqre/squareone#87 and lsst-sqre/squareone#93.
Towards the end of the month, I moved on to another Rubin web project: theming Rubin’s Sphinx documentation sites. We’re trying out pydata-sphinx-theme, which features a three column design (navigation — content — content headers) and a novel top navigation bar. Because that top navigation bar is populated from the root-level toctree elements of a Sphinx site, adopting pydata-sphinx-theme can take some content re-organization. I’ve implemented the theme in Documenteer, and I really like the result. My pull request to set up a Rubin configuration for Sphinx documentation is lsst-sqre/documenteer#129
Pursuits
Down in the wood shop (I can’t decide whether I want to call it a wood shop or workshop or even a studio) I made solid progress on my tool chest, based on the boarded chest in the Anarchist’s Design Book by Schwarz. I used my combination plane to make rabbets and nailed the chest walls together with fantastically-strong 2" cut nails. Then I used the combination plane to make tongue-and-groove joints for the bottom boards and nailed each board on, again with the 2" cut nails. I slightly mis-aligned one board while nailing it, and after failing to pull out the nails, realized that these cut nails have fantastic holding strength. I’m not worried about the chest bottom falling out. Now I’ve pivoted to making a set of low Krenovian saw horses to temporarily hold the chest at a workable height before I make a permanent stand (which could be months, years, or decades down the road).
Amanda and I got out for a bit more kayaking, and I shot and edited together a short video of us paddling around. It’s kind of dorky, but it’s also astonishing to think that we now have consumer-grade flying cameras that can follow people around perfectly.
Reading
Finished reading Hard-Boiled Wonderland and the End of the World by Haruki Murakami, The Book of M by Peng Shepard, and Boyfriend Material by Alexis Hall. Resumed the Gabriel Allon series with Amanda: we’re on The Rembrandt Affair by Daniel Silva.
Heavy rotation
The tracking on my U-Turn Orbit turntable went for a (literal) loop this month. Something about the anti-skip being a bit too strong, I think? But I really enjoyed listening to records of She & Him’s Melt Away: A Tribute to Brian Wilson and Lizzo’s Special. I must have had Sylvan Esso’s No Rules Sandy on repeat through most work days. And after watching Dua Lipa’s episode on Song Exploder, I dug a bit into her Future Nostalgia album.
Seven bees in this one sneeze weed. Our rewilding is working!


Finished reading: The Book Of M by Peng Shepherd 📚 It felt coincidental to read this right after The Hard-boiled Wonderland and the End of the World, with both speculating on the ideas of one’s shadow holding one’s soul/memories. A really lovely book with a similar slow slide into magic as Peng’s other book, The Cartographers.
A sunrise from a couple weeks ago that I got around to HDR stacking.

I’m kicking the tires on VS Code for web dev (vim+tmux user since… gosh, when did TextMate start to fall apart?). This tip for navigating splits with the keyboard is clutch → www.ryanchapin.com/vscode-ke…
Penetanguishene

I nailed together the sides of my tool chest. Used 6d (2 inch) cut nails with 2 mm pilot holes. Lots of clamping helped keep things aligned and prevented the nails from splitting the boards. 🪚



Finished reading: Boyfriend Material by Alexis Hall 📚 I sped-read this over the weekend on Amanda’s recommendation. Devestatingly adorable and full of good feels. Looking forward to the sequel!
Amanda’s purple coneflowers are a hit with the bees.

Shopping in the lettuce aisle.


Finished reading: The Hard-boiled Wonderland and the End of the World (Penguin International Writers) by Haruki Murakami. Found this book from a Carly Rae Jepson insta post (yes!) and glad I dove in to this sci-fi mediation on the mind. 📚